Offering the optimal fusion of technologies and services we support our clients to achieve and maintain the essential principles of data security: confidentiality, integrity, and availability.
Offering the optimal fusion of technologies and services we support our clients to achieve and maintain the essential principles of data security: confidentiality, integrity, and availability.
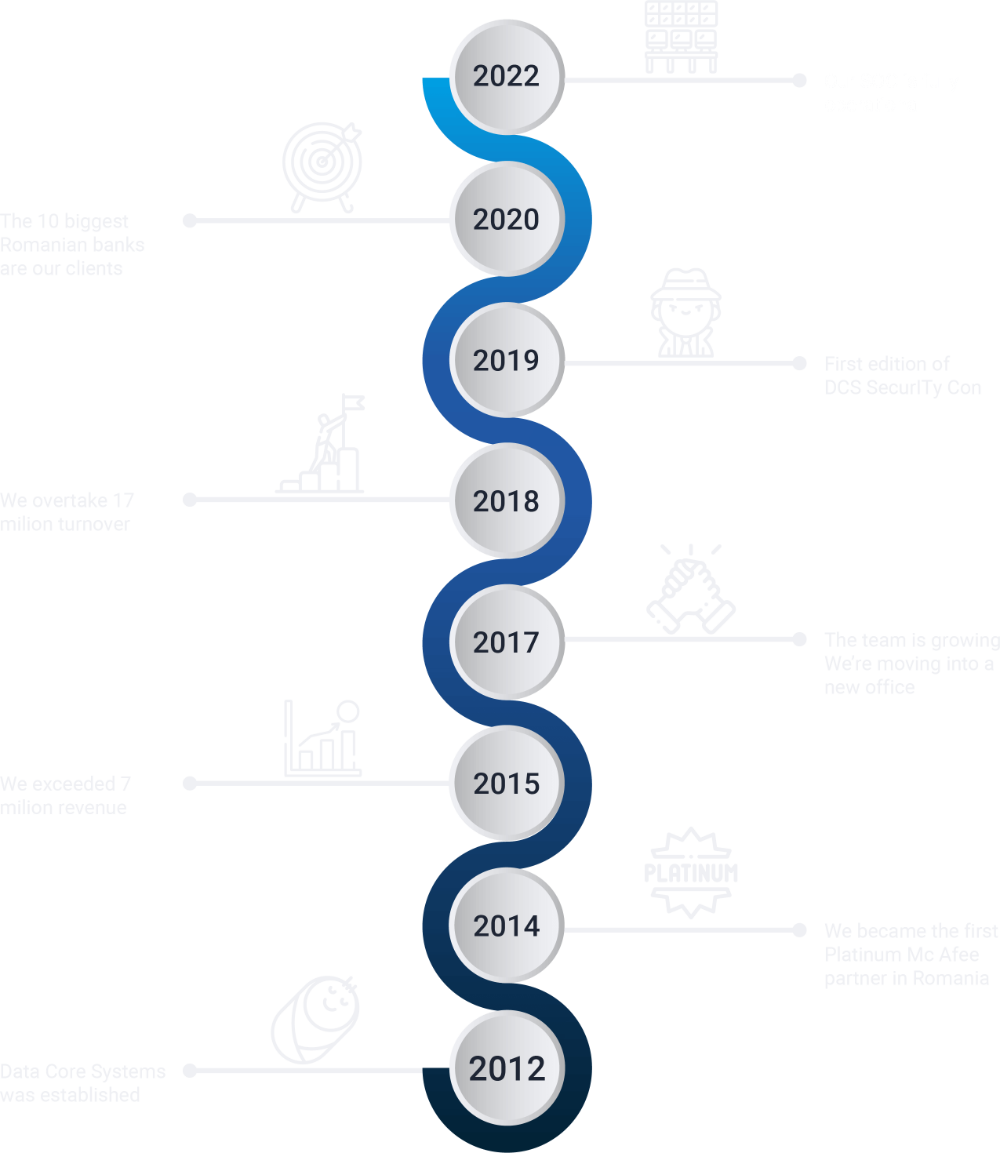
In the past 10 years, we have been helping companies choose the best security solutions, evaluate, implement and manage their infrastructure and security policies, based on a strategy tailored to their specific needs.
In the past 10 years, we have been helping companies choose the best security solutions, evaluate, implement and manage their infrastructure and security policies, based on a strategy tailored to their specific needs.